419
Amazon delivery vans were parked in bike lanes all over Cambridge today.
(mastodon.social)
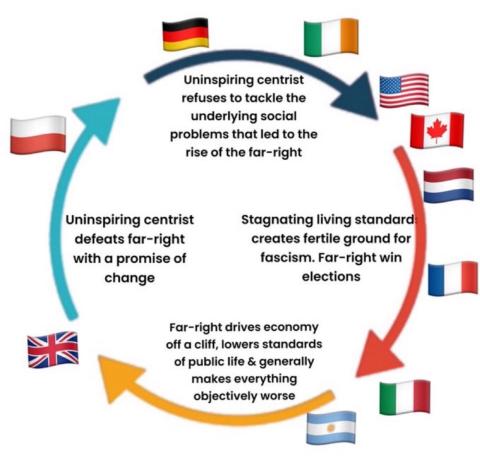
During the last decade, however, centrists and progressives alike continually fail to grasp that many voters have reached the point of ‘anything must be better than this.’
Holy fuck this is it.
This is how you elect fascists:
Once you've demonstrated that you can't be trusted, the public start to think: "Maybe the right isn't all that bad. It can't get much worse than this."
The only way to avoid fascism is to actually help the public. Gaslighting them into thinking that you're solving problems you refuse to solve only works for so long.
Agreed on all fronts. In my activism experience in Ontario specifically, I remember how the province would often push back against municipalities that wanted to build something. NIMBYism is another big problem, but the often-overlooked issue is the fact that the private sector is deliberately holding back development because it's more profitable to do so, especially when interest rates are so high.
The amount of profit in building low-rise and even high-rise (non-luxury) developments just doesn't justify the costs, and when every unit you build effectively drives down the amount you can charge for for each unit, there's simply no incentive to build at the rate we need.
There are whole swathes of undeveloped or underdeveloped land in and around cities that would benefit from a crown corporation with deep pockets that would buy up land and build affordable housing on it. A body with the power to compel companies not using land to sell it to the state so that it can be developed for the public good, and with the political cover to piss off local NIMBY organisations without having to worry about political blowback.
While I agree with you that the municipalities and provinces share a considerable amount of blame for the housing crisis, the suggestion that the federal government is somehow incapable of solving this problem is, I think, inaccurate.
I live in the UK now, where the same excuses could have been made in the 50s: the national government has no business sticking its nose into the affairs of cities and internal countries (the UK is weird). But they did it anyway. The national government spent mountains of money and resources, building an economy around building homes. The state built those homes, millions of them across the country.
Canada could do the same. Form a crown corporation that does nothing but builds high-density homes and sells or rents them at below-market rates to people in a given economic demographic. The "profit" in this model is a housing-secure nation full of happy, productive people. This, paired with an offer of big federal money exclusively for mass transit systems that connect these developments as well as a complete rollback of funding for road expansion, and Canada is well on its way to deflating the housing bubble and solving both the housing crisis and the environmental one.
But they don't want that, because the people that fund them like it when people are desperate.
Not so long as they allow him to rule like a dictator.
Also, the suggestion that they got most big policies right is laughably false. Few governments on the planet have done more to prop up the fossil fuel industry than this one, even while our country literally burns from its effects. We continue to ship weapons supplies to genociders and have some sweet fuck all about the housing crisis.
Being "not as shit as the Conservatives" is an unreasonably low bar and we can do better.
This is an excellent idea. Fortunately you're not the first to have it ;-)
You should look into alias.
Dude lives in Germany for nearly 20 years, but is still stated as "from Saudi Arabia".
I use mine with either my Jabra 75t Bluetooth earbuds, or my big Bose over-ear ones using an aftermarket Bluetooth adapter. Both are great.
From time to time, often after I've restored from sleep or finished playing a Steam game, one of my CPU cores is pinned at 100% with no indication of what might be doing it. Running htop, btop, or GNOME system monitor all show the same thing: CPU0 at 100% while the rest are doing near-nothing, and no process in particular seems to be using those resources.
If I restart, it's back to normal, and sometimes I can play a game in Steam or let the computer go to sleep and it doesn't do this, but it happens often enough that's annoying/confusing so I'd like to know if there's a way to either (a) diagnose which processes are using which CPU cores, or (b) somehow "reset" the checking of these values to make sure that something's not just being misreported.
This is a desktop system running Arch & GNOME.
Oof, that video... I don't have enough patience to put up with that sort of thing either. I wonder how plausible a complete Rust fork of the kernel would be.
Honestly, after having served on a Very Large Project with Mypy everywhere, I can categorically say that I hate it. Types are great, type checking is great, but applying it to a language designed without types in mind is a recipe for pain.
Actually, I stepped away from the project 'cause I stopped using it altogether. I started the project to satisfy the British government with their ridiculous requirements for proof of my relationship with my wife so I could live here. Once I was settled though and didn't need to be able to bring up flight itineraries from 5 years ago, it stopped being something I needed.
Well that, and lemme tell you, maintaining a popular Free software project is HARD. Everyone has an idea of where stuff should go, but most of the contributions come in piecemeal, so you're left mostly acting as the one trying to wrangle different styles and architectures into something cohesive... while you're also holding down a day job. It was stressful to say the least, and with a kid on the way, something had to give.
But every once in a while I consider installing paperless-ngx just to see how it's come along, and how much has changed. I'm absolutely delighted that it's been running and growing in my absence, and from the screenshots alone, I see that a lot of the ideas people had when I was helming made it in in the end.
Ha! I wrote it! Well the original anyway. It's been forked a few times since I stepped away.
So yeah, I think it's pretty cool 😆
I needed something for a presentation I'm doing on advanced Linux, so I thought something like this might be appropriate.
Annoyingly, I can't seem to get Bing to generate an image that isn't square.

What exactly are the risks here? Should Measles and even Polio make a comeback because of these idiots, is it just the lives of the idiots at risk, or is a resistance mutation that'd threaten everyone a risk?