Beginner questions thread
(sh.itjust.works)
3
34
6
11
Fixed it
(sh.itjust.works)
Seriously though, does anyone know how to use openwebui with the new version?
Edit: if you go into the ollama container using sudo docker exec -it bash, then you can pull models with ollama pull llama3.1:8b for example and have it.

7
17
11
34
16
18
17
38
Another day, another model.
Just one day after Meta released their new frontier models, Mistral AI surprised us with a new model, Mistral Large 2.
It's quite a big one with 123B parameters, so I'm not sure if I would be able to run it at all. However, based on their numbers, it seems to come close to GPT-4o. They claim to be on par with GPT-4o, Claude 3 Opus, and the fresh Llama 3 405B regarding coding related tasks.
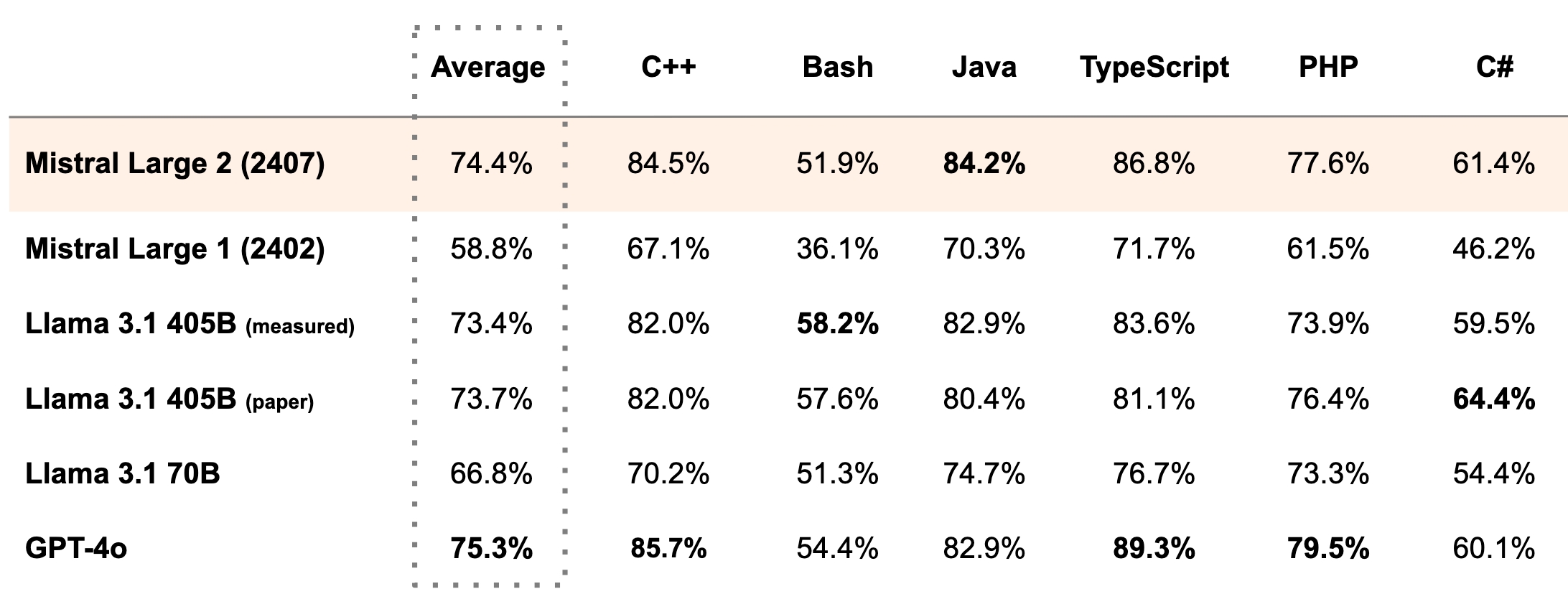
It's multilingual, and from what they said in their blog post, it was trained on a large coding data set as well covering 80+ programming languages. They also claim that it is "trained to acknowledge when it cannot find solutions or does not have sufficient information to provide a confident answer"
On the licensing side, it's free for research and non-commercial applications, but you have to pay them for commercial use.
24
24
view more: next ›
LocalLLaMA
2374 readers
6 users here now
Community to discuss about LLaMA, the large language model created by Meta AI.
This is intended to be a replacement for r/LocalLLaMA on Reddit.
founded 2 years ago
MODERATORS